在这一部分中,我们将讨论数据架构。
内容:
1. 什么是数据架构
2. Lambda vs Kappa 架构
3. 实际项目
一 什么是数据架构
数据架构是数据系统的蓝图,它服务于产品的业务需求,并描述数据如何收集、存储、转换和分发。它由需要实施和遵循的数据模型、治理策略、规则和标准组成,以构建强大且安全的数据系统。

数据架构必须满足数据系统的业务和技术需求。
业务需求可能包括以下内容:
1. 减少数据交付的延迟
2. 根据需求自动扩展数据交付
3. 为不同类型数据的数据模型增加更多灵活性
4. 提高数据质量和一致性
5. 减少存储成本和支持优化
6. 提供安全性和 GDPR 等准则合规性
支持业务的技术需求包括:
1. 业务案例的最佳数据源和摄取工具
2. 高效检索和存储优化的数据仓库解决方案
3. 定义数据相关性和消费的转换逻辑
4. 设计分析推理平台展示 KPI
5. 使用云服务进行分布式计算,以确保最低成本和不同团队的访问权限
6. 制定安全控制和监控系统以遵守法规并维护数据完整性。
以下是数据架构师职责的概述:
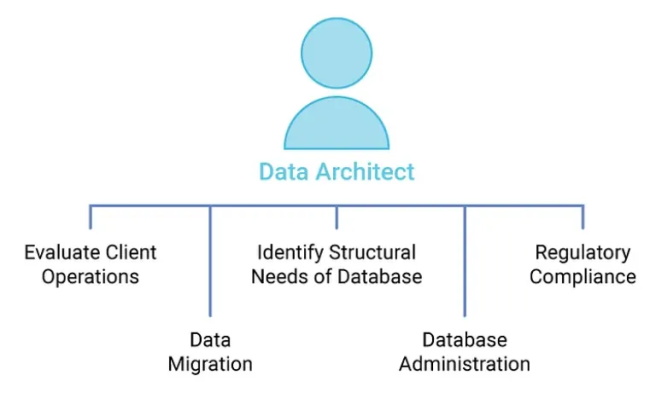

这是数据架构师和数据工程师之间的区别:二 Lambda 与 Kappa 架构
Lamba 架构被定义为具有实时和批处理能力的组合。它有 3 层:实时层,用于使用 Storm 或 Flink 等服务处理传入流;批处理层,用于使用 Hadoop 或 Spark 等服务批量处理历史数据;服务层,提供批处理和实时的组合视图数据。例如,在电子商务业务中,需要客户(批次)的购买历史记录来了解预算和质量限制,并需要实时浏览数据以提出合适的建议。
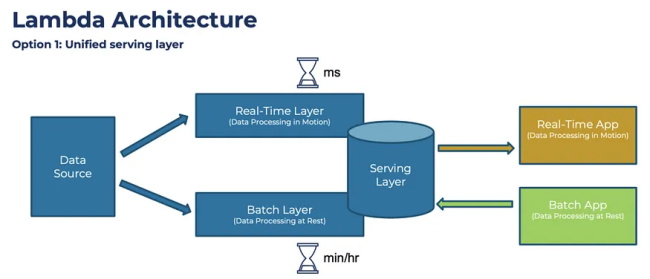
Lambda 架构面临的挑战是,您需要为实时层和批处理层复制预处理和其他常见工作,因此建议对这两种提取使用相同的服务,例如 Spark,它有助于完成这两种操作。

Kappa 架构的引入是为了采用统一的方法来应对这一挑战,并且只有一个流层,使用 Apache Kafka 等服务来处理所有操作。首先,实时数据存储在消息传递引擎中,并且可以存储在分析数据库中以便批量检索,或者根据查询类型通过服务层提供与消息传递引擎的实时交互。Kafka 是一种快速、容错且水平可扩展的服务,具有如下所示的许多功能,因此主要用于实现 Kappa 架构。

虽然 Lambda 的维护和运营成本更高,但 Kappa 使系统更加简单。但为了建立 Kappa 架构,需要不断调整它以确保可靠性和准确性。
因此,总而言之,当存在无法实时处理的大量或多种数据时,会使用 Lambda 架构,而当需要根据传入的流数据 Kappa 和中的数据立即采取行动时,会更倾向 Kappa 架构。数据具有高度一致性的情况,因此不需要太多的质量校正或复杂性。
Kappa 的一个实际用例是在 Uber 与 Kafka 一起实现的:
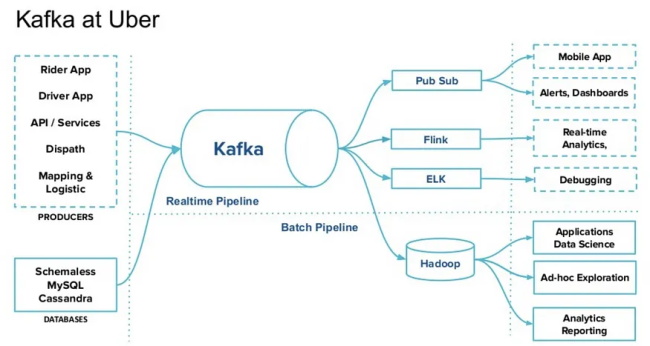
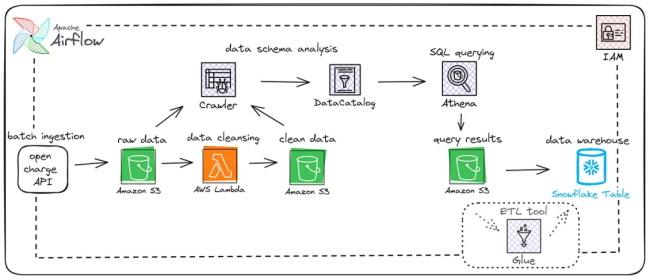
三 实际项目 电动汽车基础设施分析
这是一个已实现的实际项目及其数据架构:
问题陈述:分析电动汽车充电基础设施以识别任何模式并提出改进建议。
数据源: Open Charge API
数据编排: Airflow
数据湖: AWS S3 存储
数据架构理解: AWS Glue Crawler and Data Catalog
数据清理和预处理: AWS Lambda
ETL 和探索工具: AWS Glue 和 Athena
数据仓库和仪表板: Snowflake
数据安全:IAM
澄清:我仅在 AWS 和 Snowflake 中使用了免费套餐服务。我认为,当所有服务都在 AWS 中时,理解为什么使用 Airflow 而不是 Glue ETL 可能会令人困惑——这只是成本因素。
我在这里进行免费试用,因此存在一些限制,但如果您更舒服并且适合您的用例,您可以使用 Glue Studio 进行 ETL 和仓库连接!
我仅使用 Glue Crawler 和 Data Catalog 等 Glue 服务进行数据探索,并使用 Athena 运行 SQL 查询以确保拥有正确的结构。如果您查看代码库,就会发现与 Snowflake 的连接是通过 SQL 查询而不是 Glue。
Open Charge API
该数据源包含有关电动汽车充电站的各种信息,您可以使用经度和纬度范围进行查询,以查找该区域的电动汽车充电站。
Airflow — ELT
用于编排数据管道,并按照不同区域定期摄取API数据。
AWS Glue
AWS Glue 用于通过存储元数据的爬网程序和数据目录来理解数据架构。还可以使用 Glue通过 Glue Studio 对数据进行相关转换,然后再将其加载到 Snowflake 数据仓库中。也可以定义可从 Lambda 函数调用的 ETL 作业或对其进行调度。在ETL作业中,还可以执行数据质量检查。
AWS Lambda
它用于对原始数据进行数据清理和预处理,并将中间结果存储到另一个清理后的S3存储桶中。每次将新数据加载到原始 S3 存储桶中时,都可以触发它。
AWS Athena
可以使用 Athena 执行 SQL 查询来了解数据并将查询结果存储在分析数据库中以供数据仓库访问。
Snowflake data warehouse
它是最终用户(数据分析师)使用的分析存储,用于了解趋势和模式并构建仪表板以向相关利益相关者展示。
AWS IAM
身份和访问管理允许您设置定义对不同 AWS 资源的访问控制的角色和策略。您需要定义上述每个 AWS 资源的角色才能相互交互。
总之,使用 Airflow 从 API 进行摄取,当 S3 存储桶放置对象事件发生时会触发 Lambda,然后当有可用的清理对象时,可以使用 Snowflake 触发加载。
Snowflake中的仪表板
1.查找可用设备的数量
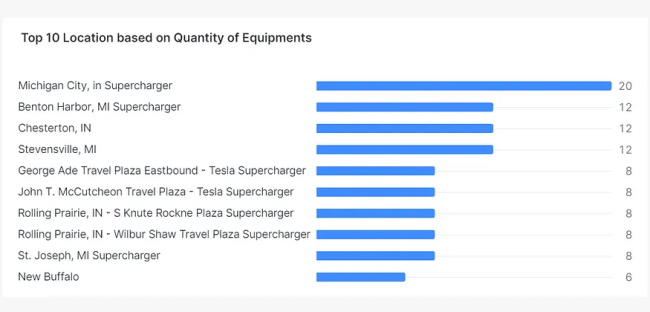
从ev_table中选择前10 个“locationtitle”、“quantity”,其中“quantity” > 1 order by “quantity” desc;2. 找出不同电流类型的功率分布情况
SELECT sum ("powerkw") as "total_power","currenttypeid" FROM ev_table

where "currenttypeid" > 1 GROUP BY "currenttypeid" ORDER BY "currenttypeid" ;3.找出电动汽车站的地理邻近性
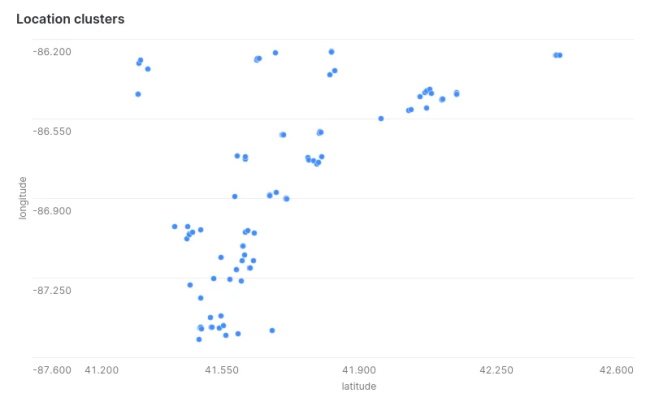
从ev_table中选择“纬度”、“经度” ;4.找出不同级别充电能力之间的功率分布

从ev_table组中按“levelid”选择“levelid”、sum(“powerkw”);5. 按充电能力等级了解位置分布
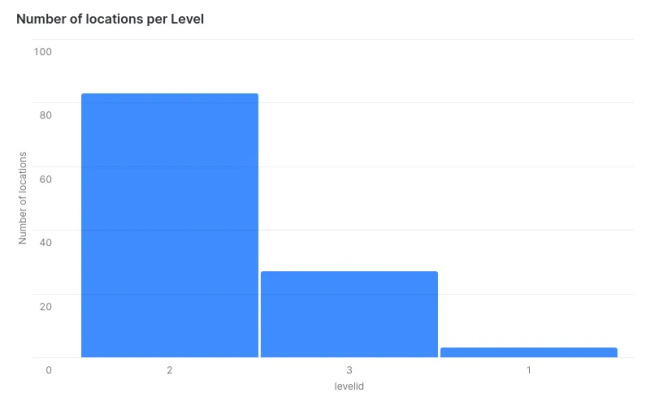
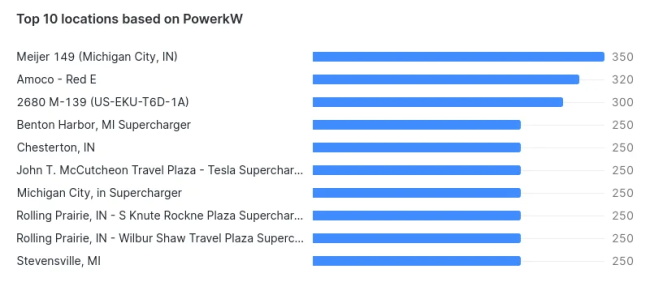
从ev_table组中按“levelid”选择计数(“locationtitle”)、“ levelid”6. 找到功率最高的位置
从ev_table中选择前10 个 “locationtitle”、“powerkw”,其中“powerkw” > 0 order by “powerkw” desc;
 数据分类分级方法、标准及应用实践
数据分类分级方法、标准及应用实践









